国际计算机视觉与模式识别会议(CVPR 2025)即将于2025年6月11日至15日在美国田纳西州纳什维尔召开,该会议是由电气电子工程师学会(IEEE)举办的计算机视觉和模式识别领域的顶级会议,属于中国计算机学会(CCF)推荐的A类国际学术会议,在Google Scholar指标榜单中位列全球学术出版物第二,仅次于Nature。本年度召开的CVPR 2025共收到13008篇有效投稿,其中2878篇被接收,录取率为22.1%。在近期公布的CVPR 2025的录取结果中,我校计算机科学与工程学院师生多项最新研究成果入选,相关简要介绍如下:
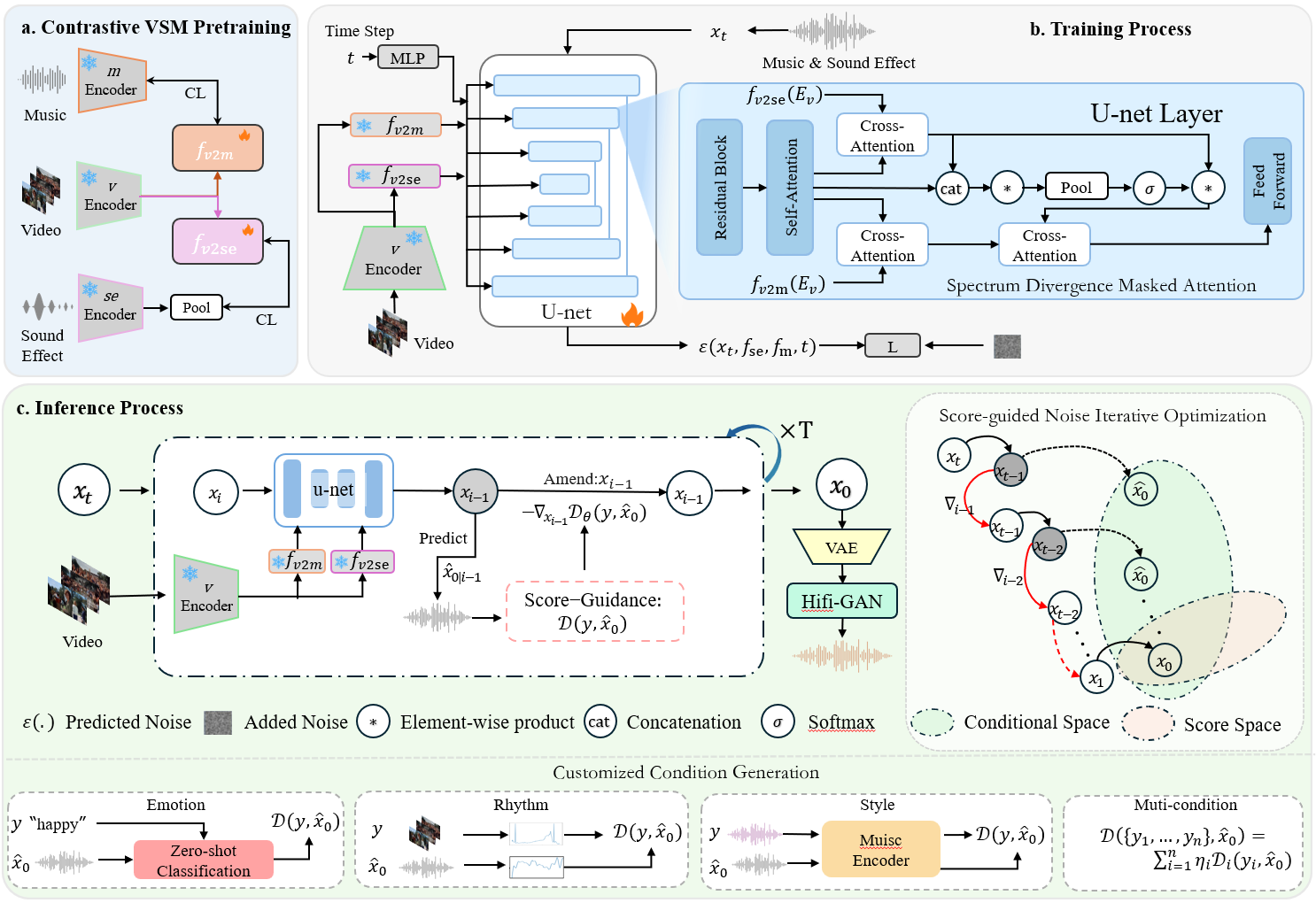
《Customized Condition Controllable Generation for Video Soundtrack》论文由学院亓帆副教授以及所指导的2023级硕士研究生马锟生撰写。该研究针对视频配乐生成领域中音乐和音效问题展开深入研究,提出了一种创新的频谱散度掩码注意力和引导噪声优化的视频配乐扩散模型框架。该框架融合对比视觉—声音—音乐预训练、频谱散度掩码注意力机制以及评分引导噪声迭代优化三大核心模块,有效地将音乐和音效这两种生成条件的模态信息映射到统一的特征空间。通过这一机制,模型在保持音效与音乐独特特性的同时,显著增强了对复杂音频动态的捕捉能力。此外,即便在视频配乐优化条件与视频信息未经复杂学习训练的情况下,该方法仍能为音乐创作者提供高度可定制的控制能力,使配乐生成过程更加灵活高效。
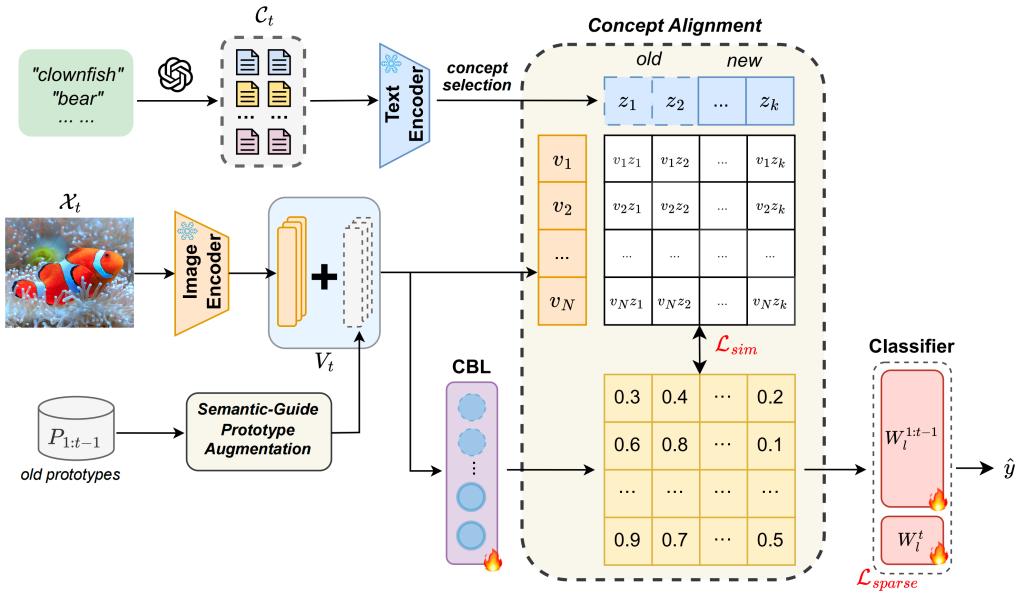
《Language Guided Concept Bottleneck Models for Interpretable Continual Learning》论文由学院余璐副教授以及所指导的2023级硕士研究生韩昊宇撰写。持续学习(Continual Learning)的目标是使学习系统能够不断获取新知识,同时不遗忘先前学习的信息。持续面临的挑战在于缓解灾难性遗忘(catastrophic forgetting)的同时保持跨任务的可解释性。现有的大多数持续方法主要侧重于保留已学知识以提高模型性能。然而,随着新信息的引入,学习过程的可解释性对于理解不断演化的决策机制至关重要,但这一方向却鲜少被探索。本研究提出了一种新颖框架,通过整合语言引导的概念瓶颈模型(Concept Bottleneck Models, CBMs)来同时应对这两大挑战。利用概念瓶颈层(Concept Bottleneck Layer),与CLIP模型对齐语义一致性,从而学习人类可理解且能跨任务泛化的概念。通过聚焦于可解释的概念,不仅增强了模型随时间推移保留知识的能力,还提供了透明的决策洞察。在多个数据集上验证了方法的有效性,其中在ImageNet子集上的最终平均准确率超越现有最优方法达3.06%。此外,通过概念可视化展示模型预测依据,进一步推动了可解释持续学习的理解。
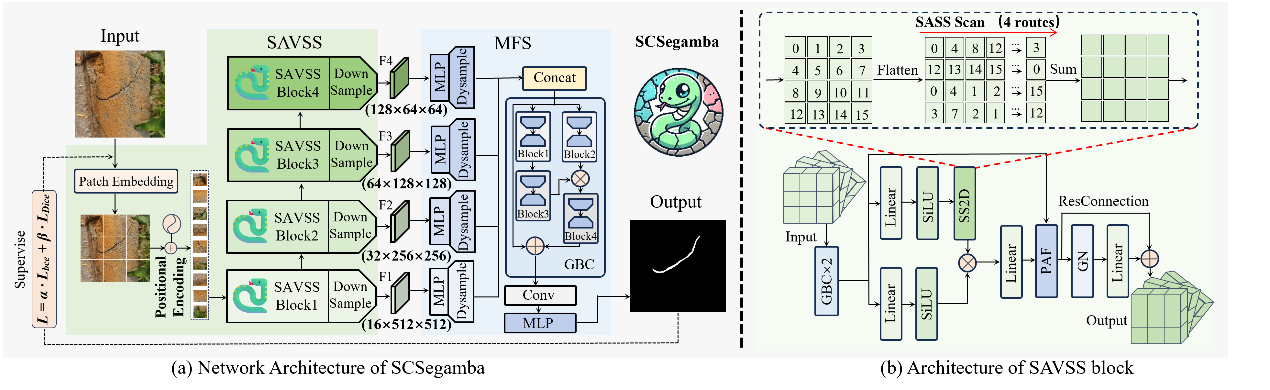
《SCSegamba: Lightweight Structure-Aware Vision Mamba for Crack Segmentation in Structures》论文由学院石凡教授和程徐教授所指导的2023级硕士研究生刘辉撰写,通讯作者为贾晨博士后。该研究提出了一种面向边缘设备优化的轻量化结构感知视觉Mamba网络SCSegamba,通过动态特征建模机制与极简高效的设计实现了复杂场景下的高精度裂缝分割。其核心创新在于首先基于低秩分解与动态门控机制设计了轻量级门控瓶颈卷积,相比于标准卷积,低秩分解使得网络的参数规模和GFLOPs分别降低了64.60%和71.63%,在大幅减少计算需求的同时保持了裂缝形态特征提取能力;结构感知状态空间模块利用创新性的多路径结构感知扫描策略感知裂缝像素之间的拓扑结构邻接关系,提高了特征图的语义连续性,相比于传统的平行扫描策略,在F1和mIoU上分别提高了1.19%和0.84%;此外,轻量级的多尺度特征分割头能够以极低的0.01M参数规模和0.42GFLOPs的计算需求生成有效抑制背景噪声的高质量分割图。该网络模型总体仅具有2.80M参数规模与18.16GFLOPs,特别是与基于轻量Transformer的方法相比,参数规模减少了52.54%。在包含低对比度、多光照条件和复杂背景噪声等挑战性场景的结构裂缝检测数据集上,该网络的F1分数和mIoU指标分别达到了0.8390和0.8479,与次好的方法相比分别提高了2.22%和1.74%,展现出最优性能表现,为边缘计算设备上的实时结构裂缝检测提供了可行的轻量化解决方案。
学校始终坚持以国家战略需求为导向,以智能技术创新为驱动,持续深耕人工智能和计算机视觉等前沿领域。此次多项成果入选CVPR 2025,标志着学校在人工智能、计算机视觉及交叉领域的研究取得新的突破。



